An Empirical Study on Information Extraction using Large Language Models
Jun 22, 2023· ,,,,,·
0 min read
,,,,,·
0 min read
Ridong Han
Chaohao Yang
Tao Peng
Prayag Tiwari
Xiang Wan
Lu Liu
Benyou Wang
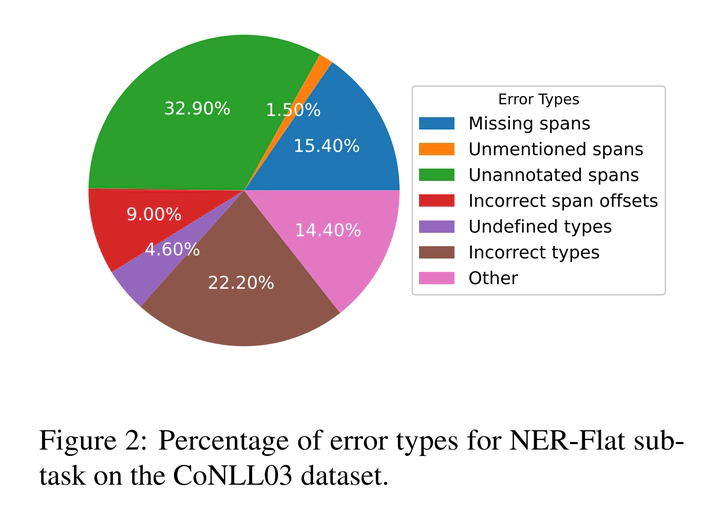
Abstract
Human-like large language models (LLMs), especially the most powerful and popular ones in OpenAI’s GPT family, have proven to be very helpful for many natural language processing (NLP) related tasks. Therefore, various attempts have been made to apply LLMs to information extraction (IE), which is a fundamental NLP task that involves extracting information from unstructured plain text. To demonstrate the latest representative progress in LLMs’ information extraction ability, we assess the information extraction ability of GPT-4 (the latest version of GPT at the time of writing this paper) from four perspectives: Performance, Evaluation Criteria, Robustness, and Error Types. Our results suggest a visible performance gap between GPT-4 and state-of-the-art (SOTA) IE methods. To alleviate this problem, considering the LLMs’ human-like characteristics, we propose and analyze the effects of a series of simple prompt-based methods, which can be generalized to other LLMs and NLP tasks. Rich experiments show our methods’ effectiveness and some of their remaining issues in improving GPT-4’s information extraction ability.
Type