Q-Adam-mini: Memory-Efficient 8-bit Quantized Optimizer for Large Language Model Training
May 31, 2025· ,,,·
0 min read
,,,·
0 min read
Yizhou Han
Chaohao Yang
Congliang Chen
Xingjian Wang
Ruoyu Sun
Abstract
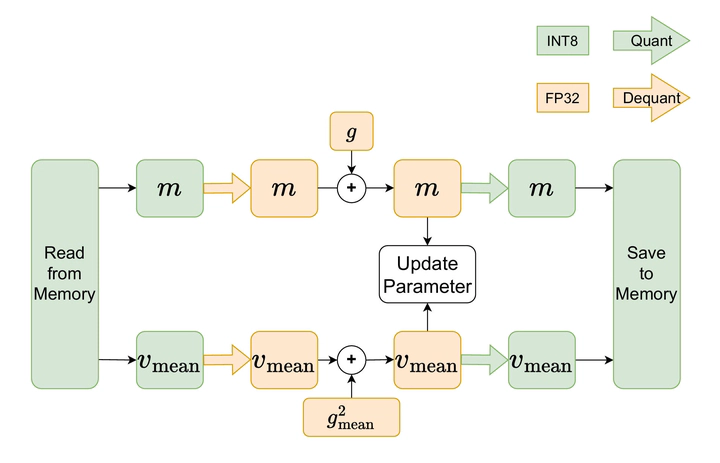
We propose Q-Adam-mini, a memory-efficient optimizer for Large Language Model (LLM) training that achieves 8x reduction in GPU memory usage while maintaining performance parity with full-precision AdamW. Building upon Adam-mini, which reduces memory footprint of optimizer states by 50% compared to AdamW, we further improve memory efficiency through states quantization. We achieve this by: (i) quantizing the first-order momentum (m) to INT8 and (ii) retaining the second-order momentum (v) in FP32, which occupies less than 1% of total memory. However, embedding layer exhibits weight norm instability. We analyze this issue and address it by applying stochastic rounding for momentum quantization exclusively to the embedding layer. We validate our approach on both pre-training and fine-tuning tasks, with the model size ranging from 60M to 8B. Our results demonstrate that Q-Adam-mini enables scalable LLM training with limited computational resources.
Type